
There are several great use cases of entity recognition on search terms in Google Ads. In this post you’ll find out how to optimize your Google Ads accounts with a step by step guide to build a custom entity database.
Entity recognition is an information extraction technique. It identifies and classifies the named entities in a text and puts them into pre-defined categories. These entities can be names, locations, times, organizations and many other key informations you can imagine. Based on your business you will have different entities. Let’s say you sell a variety of products. For each product you normally have a brand name, specific product identifiers such as color, size, etc.
You might already be using entities for deriving keywords based on product feed data by concatenating different columns. Now think of inverting the whole process of keyword generation. You’ll start with all types of user queries and want to extract components to get structured queries.
How to use discovered entity patterns
Google Shopping campaigns or dynamic search ads are a great way to discover new relevant search queries. Of course, there will also be a lot of bad ones that should be blocked. Using N-gram analysis provide great insights but sometimes it may not be enough. Mapping all performance data to extracted entities will give you new insights.
- There will be bad patterns that should be blocked. This is one frequent entity pattern in queries for larger companies:
[%yourBrand%] [%first name or surname%]
This means that the users aren’t searching for your brand to buy something – they search for people working in your company.
There are thousands of names that can be looked up in databases. Many of them don’t have enough clicks to be discovered in N-gram analysis. With the entity aggregation you’ll be able to see these patterns. A common action would be to negativate those words. - For a second great use case, think of a user driven account structure. Based on well performing entity patterns you can easily derive a logical grouped account structure in a granular way.
The better your initial input is (e.g. your product attributes), the better the entity recognition will be.
Share on Twitter
A step-by-step guide to build a custom entity database
- A great starting point is your product master data – a lot of attributes can be easily accessed by using existing product feeds (e.g. the ones you use for Google Shopping)
- Use your domain knowledge to entities: competitor names, cities, transactional keywords, etc. There are a lot of lists out there that can be used for this.
- Enrich your list of step 1 and 2 with automatically detected close variants and similar entities. We do this by using stemming algorithms, distance algorithms and neural networks (word2vec implementation)
This may sound like a boring theory but let’s see it in action. Here’s a real word example for a customer of us who sells software.
We feed the system with a first entity “operating system” and assign two values: “Windows” and “Linux”. That’s it.
This is what we get when we query our neural net:
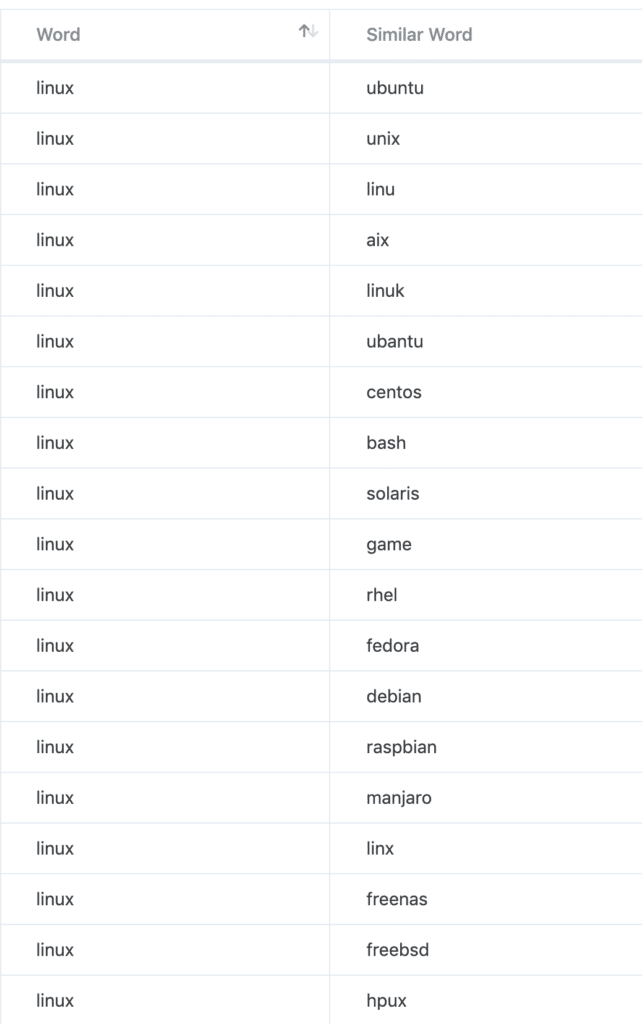
Without any knowledge of Linux, we get a list of linux/unix distributions and misspellings out of the neural network that was trained with a full year of customers search queries.
We know some distributions like “debian” or “ubuntu”. After a quick Google research for the unknown words, we added everything except “game” and “bash” to my list of operating systems. Pretty nice, isn’t it?
This is some initial work but it is worth it! And remember; the better your initial input is (e.g. your product attributes) the better the entity recognition will be. In the end we have a fully tailored entity lookup list that can be used to label every search query with found entities.
In our simple example, we looped over all search queries — whenever we found a key that’s contained in our entity database we assigned the full query a tag with “Operating System”. Of course also multiple tags will be very common.
New insights for “low sample size” elements
To explain the benefit of this approach, I’ll give you an example of identifying negative keywords. In this case, a game (online, desktop, mobile, etc.) is part of the search query.
- Filter for performance outliers on query level with enough sample data → 0 results
- Filter on 1-grams with enough sample data → 1 result: “fortnite”
- Query the neural net with “fortnite”.
In total the savings of the “hidden” games were many times higher than our input “fortnite”. Of course these games will pop up after a few months as bad 1-grams. By then a chunk of your budget have already been wasted. This approach lets us to set negatives in a very early stage.
Currently we run python scripts for those analysis procedures for some of our larger clients. If you’re interested in a web based application for your business, apply for PhraseOn Beta.
Key takeaways
🔵 You can discover relevant search queries through Google Shopping campaigns or dynamic search ads. Mapping all performance data to extracted entities will give you new insights.
🔵 Based on well performing entity patterns you can easily derive a logical grouped account structure in a granular way.
🔵 You can set negatives at a very early stage and save considerable budget.